




Initially, my project focused on BuildingBrands, but after re-evaluating my interests and goals, I decided to pivot towards a more challenging and personal direction. I reframed the project around the research question: “What insights can be gained from intercepting the personal data collected by my technology and apps?” This pivot led me to explore how seemingly disconnected data points could be aggregated to form a comprehensive narrative, not only about who I am but also about predicting future trends and understanding past behaviour. With Gen Z being relatively relaxed about data privacy, my goal is to help users visualise their personal data, similar to how Spotify Wrapped summarises musical preferences. Inspired by studies like (Nicol, et al., 2022), who studied the cumulative risks of online personal information, revealing current difficulties in conceptualising digital traces and understanding how information may be combined across platforms.
A Place Where All Data Comes Together
One of the major hurdles was finding a platform that could merge all this diverse data into something that users could easily interpret. Inspired by projects such as ReelOut, created by (Farrow, et al., 2013) which is an application that constructs stories from social media data using sentiment, themes, and named entities. The initial idea was to use ChatGPT for such data processing, but its 500-character limit per file proved practically unusable for my use-case.

This challenge led me to experiment with Glide, which integrates GPT-4 into its database functionality.
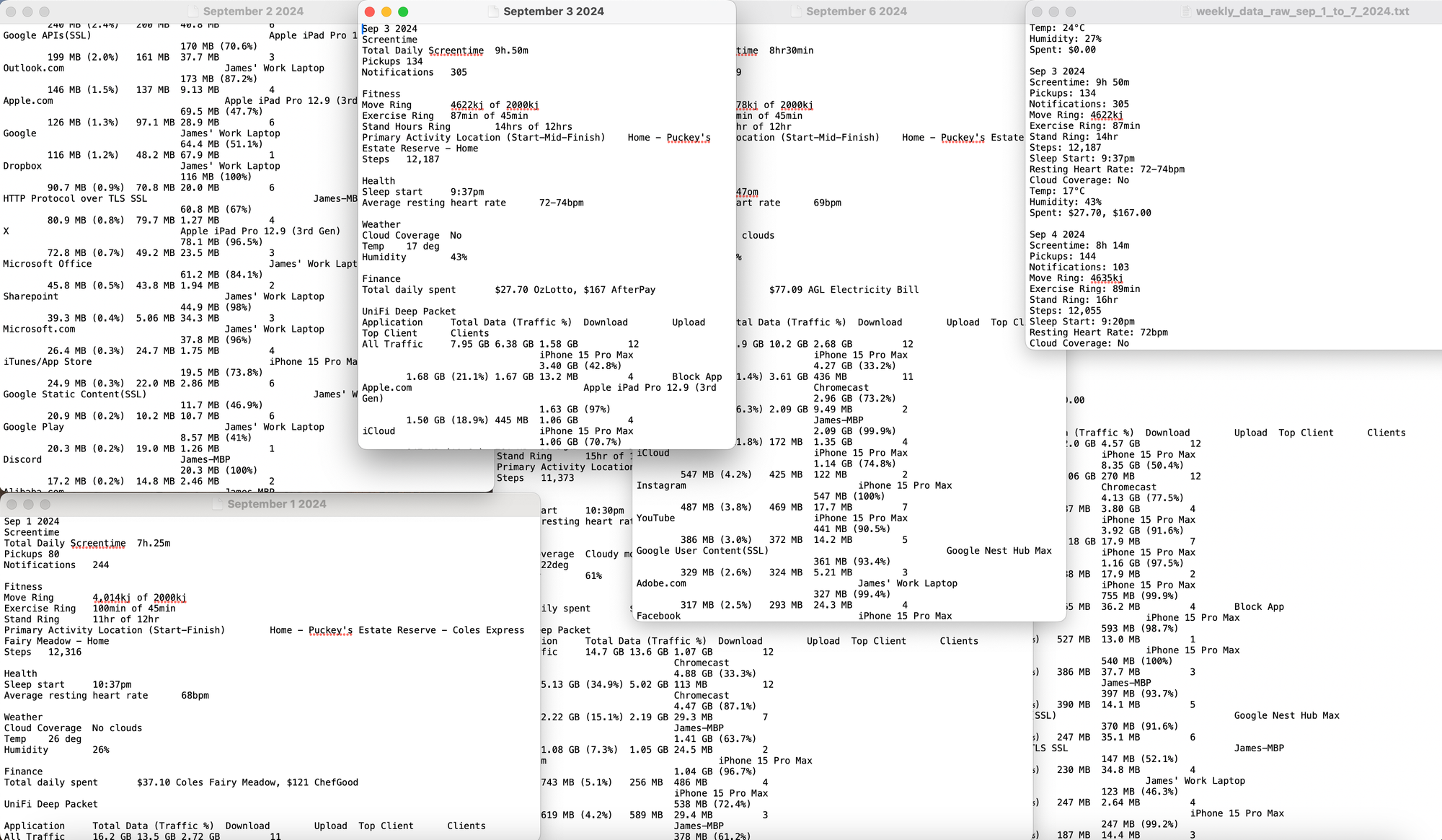
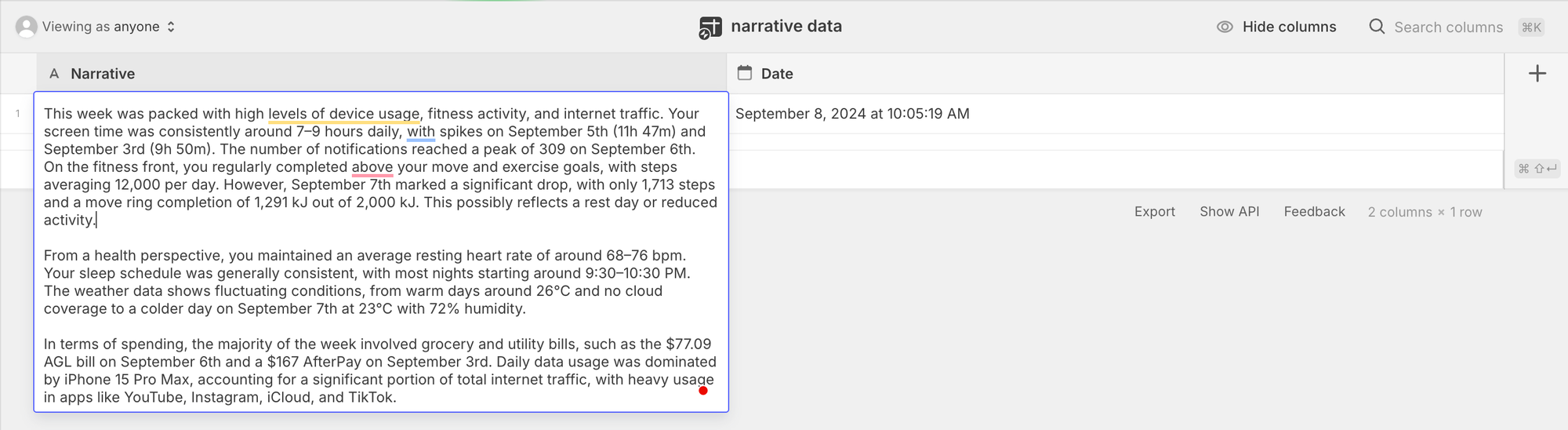
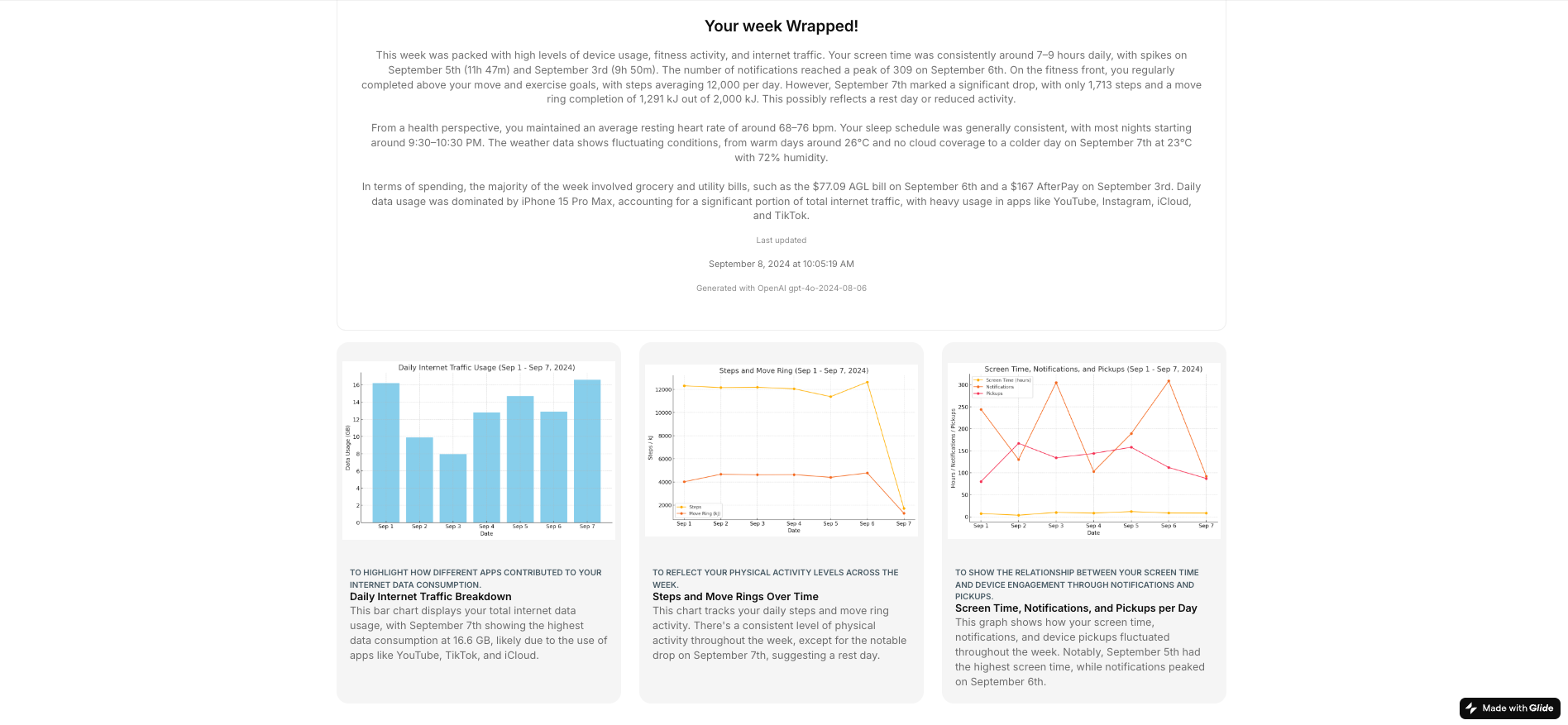
By recontextualising the intercepted data into weekly summaries, I was able to develop more accessible data visualisations and text summaries, similar to Spotify Wrapped. This application of exaptation—repurposing Glide for data aggregation—helped me realise that existing tools can serve purposes far beyond their original design (Garud, et al., 2016). By exploring the adjacent possibilities of functionality (like overcoming ChatGPT’s character processing limitations) I've established new opportunities for exploring richer datasets and creating more personalised user experiences.

Establishing Additional Data Streams
After processing my initial dataset, I realised that the data wasn’t as holistic as I had expected. This led to another key learning moment: expanding my data capture methods. I began incorporating new streams, including GPS data from apps like Life360, a family-tracking app not typically intended for projects like mine. Here, the concept of exaptation came into play again. Similarly, I integrated my banking data, importing daily transactional summaries, which added an entirely new dimension to the dataset.
This iterative process led me to explore more unconventional data sources, asking ChatGPT for suggestions on what else could be incorporated to build a complete picture of my daily digital footprint. As i began adding additional data streams, my data summaries began to get more intricate and detailed, making assumptions and predictions based on existing data, such as that i work from home due to the large amount of productivity apps used on the WiFi during business hours.








This weeks daily context photos

As I began collecting browser history, app usage details, and recently even my calendar data and a daily image from my camera roll, I noticed another adjacent possible which opened new pathways for media creation, such as personalised recaps of my daily activity or generating insights based on my financial transactions. (Aylett, et al., 2015) developed algorithms to select Instagram images, which produced story-like sequences, I want to also attempt to integrate a visual imagery component into my daily data set as each new stream enhances the narrative, providing users with insights that wouldn’t be possible without the combination of multiple data points. This demonstrates the cumulative risks described by (Nicol, et al., 2022), where the aggregation of data across platforms can create an intricate, deeply personal narrative.

This weeks 'Wrapped'

Automating for Project Sustainability
Throughout the early stages of this project, I had realisation that manually collecting and processing data is neither scalable nor sustainable. Automation is vital for the project to continue evolving beyond the semester. I started researching tools like iTools, which, while not explicitly designed for data interception, allows for bulk exports of app data—an important step forward.

Antifragility, coined by Nassim Nicholas Taleb, involves initiatives that benefit from adversities. By automating this data collection process, the project aligns with antifragility, where systems improve and adapt when exposed to stress (Taleb, 2012). In this context, automation allows the project to become more resilient, capable of maintaining accuracy even if human input is inconsistent. My overall goal is to create a dataset so detailed and strong, that even if i was to miss a day of data collection, the system can learn from previous patterns and fill in the gaps, turning potential failure into an opportunity for further insight.
The resilient resists shocks and stays the same; the antifragile gets better (Taleb, 2012)
From this, the identified adjacent possibles of this project could evolve into a personal assistant that offers daily insights based on users’ data? Could it predict trends or suggest actions based on accumulated behavioural patterns? By thinking in terms of future possibilities, I’m positioning the project to continue evolving in ways that might not have been apparent at the start. I’m also exploring how this automated system could serve the general public, offering them detailed data narratives to make sense of their digital footprints.
Next Steps
What began as a simple data collection project has grown into something far more ambitious. By repurposing existing tools, expanding my dataset, and automating processes for sustainability, I am building a digital artefact that educates users about the narratives embedded in their personal data. Moving forward, I am excited to explore how AI and automation can further enhance the storytelling capacity of this project, making personal data more meaningful and accessible to users in new and engaging ways and develop user-friendly data visualisation, to help make sense of this project.
Sources
Aylett, M., Farrow, E., Pschetz, L. & Dickinson, T., 2015. Generating Narratives from Personal Digital Data. Seoul, CHI, the 33rd Annual ACM Conference Extended Abstracts.
Farrow, E., Dickinson, T. & Aylett, M., 2013. Generating Narratives from Personal Digital Data: Using Sentiment, Themes, and Named Entities to Construct Stories. Cape Town, South Africa, IFIP TC13 International Conference on Human-Computer Interaction.
Garud, R., Gehman, J. & Giuliani, A., 2016. Technological Exaptation: A Narrative Approach. Industrial and Corporate Change, 25(1), p. 149–166.
Glide, 2024. Glide Apps - No Code Apps. [Online]
Available at: https://www.glideapps.com/
[Accessed 14 09 2024].
Life360, 2024. Life360. [Online]
Available at: https://www.life360.com/au/
[Accessed 14 09 2024].
McTaggart, J., 2024. BuildingBrands for BCM302. [Online]
Available at: https://uow.jamesmctaggart.com/buildingbrands-for-bcm302/
[Accessed 11 09 2024].
Nicol, E. et al., 2022. Revealing Cumulative Risks in Online Personal Information. Proceedings of the ACM on Human-Computer Interaction, Volume 6, pp. Pages 1 - 25.
Sloan, A., 2024. Generation Z and Data Privacy: When People Stop Caring. [Online]
Available at: https://blogs.elon.edu/publicpolicythinktank23/2024/03/06/generation-z-and-data-privacy-when-people-stop-caring/
[Accessed 12 09 2024].
Taleb, N. N., 2012. Antifragile: Things That Gain from Disorder. 1 ed. s.l.:Random House .
ThinkSkySoft, 2024. iTools. [Online]
Available at: https://www.thinkskysoft.com/itools/
[Accessed 14 09 2024].

